
. با توجه به نسبتا مفصل بودن مباحث رگرسیون پانل دیتا در این صفحه، از فهرست زیر استفاده نمایید. با کلیک بر روی عنوان مرور گر به سر خط مبحث مد نظر خواهد رفت و با کلیک بر روی {برو به فهرست} به فهرست مطالب باز خواهید گشت.
فهرست مطالب:
1- داده های پانل چگونه داده هایی هستند؟
2- تعریف داده های تابلویی (پانلی)
6- تفاوت مدل پانل (panel) با مدل تجمیعی (pooled) پولین
7- آزمون قابلیت برآورد الگو به صورت پانل (آزمون F لیمر يا چاو)
10- آزمون هاسمن برای تشخیص مدل اثر تصادفی از مدل اثر ثابت
11- آزمون ریشه واحد برای بررسی پایایی متغیرها در پانل دیتا
12- نقض فرض نرمال بودن در داده های پانل، بررسی خودهمبستگی و ناهمسانی واریانس
13- پانل دیتا در پایان نامه ها و مقالات
14- تحلیل پانل دیتا با eviews ایویوز
1-14- قبول سفارش تحلیل پانل دیتا (فصل چهار پایان نامه)
2-14- آموزش ورود داده های پانل به EViews
دیدن بسته آموزشی : نمونه فصل 4 پایان نامه پانل دیتا
دیدن بسته آموزشی : نمونه فصل 3 پایان نامه پانل دیتا
فیلم مفهوم داده های تابلویی (پانل)
اگر در خصوص اینکه دقیقا داده های پانل چطور داده هایی هستند ابهام دارید و مایلید مثالهایی از آن را ببینید، حتما این فیلم 10 دقیقه ای را ببینید:
همچنین چنانچه مایلید آموزش جامع، ویدئویی و گام به گام رگرسیون داده های پانلی را دریافت دارید، لینک زیر را ببینید:
توضحیات آموزش جامع پنل دیتا به قرار ویدئوی زیر است:
1- داده های پانل چگونه داده هایی هستند؟
{برو به فهرست} می خواهیم در این خصوص صحبت کنیم که داده هاي ترکيبي يا پانل ديتا (که به آن داده های تابلویی یا داده های تلفیقی نیز می گویند) چگونه داده هايي هستند؟ ابتدا تعریف داده های ترکیبی یا پانل دیتا:
2- تعریف داده های پانلی
داده های پانلی یا ترکیبی، مجموعه ای از داده ها هستند که شامل چند مقطع و یک دوره زمانی می باشند. مقطع می تواند بیانگر افراد، گروه ها، بنگاه ها، صنایع، کشورها و . . . باشد، که البته مقطع معمولا شرکتهای بازار بورس یا کشورها می باشد. دوره زمانی نیز چند سال یا چند نیم سال می باشد. {برو به فهرست}
در یک تعریف عملیاتی، داده های پانل داده هایی هستند که به جای یک بعد (که معمولا سال ها است)، دارای دو بعد زمان (سال) و مقطع (شرکتها) می باشد. به همین دلیل دو بعدی بودن از نام های داده های ترکیبی یا داده های تابلویی برای آن استفاده می شود.
پانل متوازن: اگر تعداد مشاهدات زمانی برای تمام مؤلفههای موجود در پانل یکسان باشد، به آن پانل متوازن (Balanced Panel) گفته میشود، اما درصورتیکه مشاهدات گمشده یا مفقودی برای تعدادی از متغیرها داشته باشیم، پانل را نامتوازن می گوییم.
توضیح بیشتر این است که
3- در مباحث اقتصادسنجی داده ها دارای سه حالت می باشند:
- سری های زمانی: که در آن داده هایی را بر حسب زمان در اختیار داریم. مثل نرخ تورم کشور طی 20 سال اخیر.
- داده های مقطعی: که در آن داده هایی را بر حسب مقاطع (نام شرکتها یا نام کشورها) در اختیار داریم. توجه شود که در اینجا زمان ثابت فرض می شود. مثل نرخ تورم در کشورهای اپک در سال 1395.
- داده های ترکیبی (پانل): در این نوع داده ها هر دو بعد فوق را داریم. به عبارت دیگر داده هایی داریم که در آنها هم سری زمانی است و هم مقاطع مختلف. مثل نرخ تورم در کشورهای اپک طی 20 سال اخیر.
{برو به فهرست} به نظرم اکنون برای شما روشن شد که پانل دیتا چیست. در ادامه بیشتر و کامل تر این مفهوم را روشن خواهیم ساخت و پیرامون آن صحبت خواهیم کرد. پانل دیتا بسیار پر کاربرد است و می توان گفت رویه های تحلیلی خاص خود را در اقتصاد سنجی و نرم افزار ایویوز دارد.
4- مثالی از داده های پانل
به عنوان مثال در تصویر زیر داده های ترکیبی یا پانل را در اکسل مشاهده می نمایید:

همانگونه که ملاحظه می شود در تصویر فوق اطلاعات شرکتهای بازار بورس را طی سالهای1385 تا 1394 ، و به تفکیک شرکتهای مختلف بورسی به صورت همزمان و ترکیبی و به عبارت فنی: پانل داریم. {برو به فهرست}
در مثال فوق چنانچه فقط داده های یک شرکت را طی سال های مختلف بررسی کنیم، سری زمانی و چنانچه فقط داده های شرکت های مختلف بورسی را در یک سال بررسی کنیم، داده های مقطعی خواهیم داشت. پنل دیتا ترکیبی از این دو است.
5- مزایای پانل دیتا
حال به مزایای استفاده از داده های پانل دیتا می پردازیم. بهرحال این نوع داده ها مزایای خوبی دارند که باعث شده اینطور گسترده به کار گرفته شوند. این بخش از مطلب از کتاب “تجزیه و تحلیل آماری با EViews” آقای دکتر عباس افلاطونی، استخراج شده است.

- با ترکیب مشاهدات سری زمانی و مقطعی، داده های ترکیبی اطلاعات بیشتر، تغییر پذیری بیشتر، هم خطی کمتر میان متغیرها، درجات آزادی بیشتر و کارایی بیشتری را ارائه می کنند.
- در مطالعه مشاهدات مقطعی تکراری، داده های ترکیبی به منظور مطالعه پویای تغییرات مناسب تر و بهترند. دوره های بیکاری، چرخش شغلی و تحرک نیروی کار با داده های ترکیبی بهتر بررسی می شوند.
- داده های ترکیبی، تاثیراتی را که نمی توان به سادگی در داده های سری زمانی و مقطعی مشاهده کرد، بهتر معین می کنند. برای مثال، اگر نوسان پیاپی افزایش حداقل دستمزد را در حداقل دستمزد بررسی کنیم، اثرات قوانین حداقل دستمزد را بر اشتغال و کسب درآمد بهتر می توان مطالعه کرد.
- داده های ترکیبی با ارائه داده برای هزاران واحد، می توانند تورشی را که ممکن است در نتیجه لحاظ افراد یا بنگاه های اقتصادی (به صورت جمعی و کلی) حاصل شود، به حداقل برسانند.
- از آنجا که داده های ترکیبی به افراد، بنگاه ها، شرکتها و کشورها و از این قبیل واحدها، در طی زمان ارتباط دارند، وجود ناهمسانی واریانس در این واحدها محدود می شود. {برو به فهرست}
به طور کلی باید گفت، داده های ترکیبی، تحلیل های تجربی را به شکلی غنی می سازند که در صورت استفاده از داده های سری زمانی یا مقطعی این امکان وجود ندارد. البته نمی توان گفت که مدل سازی با داده های ترکیبی هیچ مشکلی ندارد.
6- تفاوت مدل پانل (panel) با مدل تجمیعی (pooled)
حال تفاوت داده های panel با pooled یا بهتر بگوییم تفاوت مدل های پانل با پولد (تجمیعی که پولینگ هم می گویند) را توضیح می دهیم.
مدل تجمیعی یا پولد (که به آن مقید نیز می گویند) بیانگر آن است که اثرات فردی وجود ندارد و {عرض از مبدا} همه گروه ها یکسان هستند.
در برآورد یک مدل رگرسیون با داده های پانل، وقتی که به این نتیجه می رسیم که در مدل خود، عامل مقطع (کشورها یا شرکتها) یا عامل زمان (سال) را می توانیم نادیده بگیریم و تفاوت معنی داری بین کشورهای مختلف یا شرکتهای مختلف وجود ندارد، می گوییم داده ها pooled (پول) هستند. به عبارت دیگر وقتی مدل ما پانل نباشد، مدل pooled می باشد.
به زبان ساده، وقتی مقاطع و زمان باعث اتفاق خاصی در مدل رگرسیون ما نشده و می توانیم آنها را نادیده بگیریم، به یک رگرسیون معمولی بر روی داده ها و متغیرها خواهیم رسید که به به آن مدل پولد یا تجمیعی یا مقید می گویند.
برای سنجش اینکه داده ها پانل هستند یا پولد (pooled) از آزمون اف لیمیر (که آزمون چاو نیز می گویند) {Limier -Chow} استفاده می شود. بهرحال وقتی داده پولد نبودند یا پانل با اثرات ثابت هستند و یا پانل با اثرات تصادفی. {برو به فهرست}
توجه شود که آزمون هاسمن برای مرحله بعدی و بعد از آزمون اف لیمر استفاده می شود. یعنی وقتی که متوجه شدیم با مدل پانل مواجه هستیم و در نتیجه اثرات ثابت یا تصادفی وجود دارد، از آزمون هاسمن برای تعیین مدل با اثرات ثابت و یا مدل با اثرات تصادفی استفاده می کنیم.
7- آزمون قابلیت برآورد الگو به صورت پانل (آزمون F لیمر يا چاو)
در بررسی دادههای مقطعی و سریهای زمانی، اگر ضرایب اثرات مقطعی و اثرات زمانی معنیدار نشود، میتوان دادهها را با یکدیگر ترکیب کرده و به وسیله یک رگرسیون حداقل مربعات معمولی تخمین بزنیم (مدل تجمیعی یا پولد). از آنجایی که در اکثر دادههای ترکیبی اغلب ضرایب مقاطع یا سریهای زمانی معنیدار هستند این مدل که به مدل رگرسیون تجمیعی یا پولد (مقید) معروف است کمتر مورد استفاده قرار میگیرد.
بنابراین برای اینکه بتوان مشخص نمود که آیا دادههای پانل برای برآورد تابع موردنظر کارآمدتر خواهد بود یا نه، فرضیه ای را آزمون می کنیم که در آن کلیه عرض از مبدا ها (عبارات ثابت برآورد) با یکدیگر برابر هستند.
فرضیه صفر این آزمون که به آزمون چاو یا اف لیمر معروف است، بهصورت زیر میباشد:

در این آزمون فرضیه H0 یعنی یکسان بودن عرض از مبداءها در مقابل فرضیه H1 یعنی ناهمسانی عرض از مبداءها قرار میگیرد. در صورتی که فرضیه H0 پذیرفته شود به معنی یکسان بودن شیبها برای مقاطع مختلف بوده و قابلیت ترکیب شدن دادهها و استفاده از مدل رگرسیون ترکیب شده مورد تأیید آماری قرار میگیرد و فرضيههاي پژوهش با استفاده از روش دادههاي تركيب شده مورد آزمون قرار خواهد گرفت. {برو به فهرست}
اما در صورت رد فرضیه H0 روش دادههای پانل پذیرفته میشود و فرضيههاي پژوهش با استفاده از روش دادههاي پانل آزمون ميشود.
8- مدل با اثرات ثابت چیست؟
برای توضیح مدل با اثرات ثابت، فرض کنید مدل رگرسیون پانل ما به قرار زیر باشد:
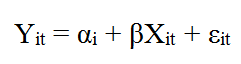
که در آن Y متغیر وابسته و X متغیر مستقل است. α نیز عرض از مبدا رگرسیون بوده و ε نیز جمله خطا (یا اخلال یا باقیمانده مدل) است. تصویر زیر نیز خط رگرسیون (قرمز رنگ) که بر داده ها برازش داده شده است را نشان می دهد.
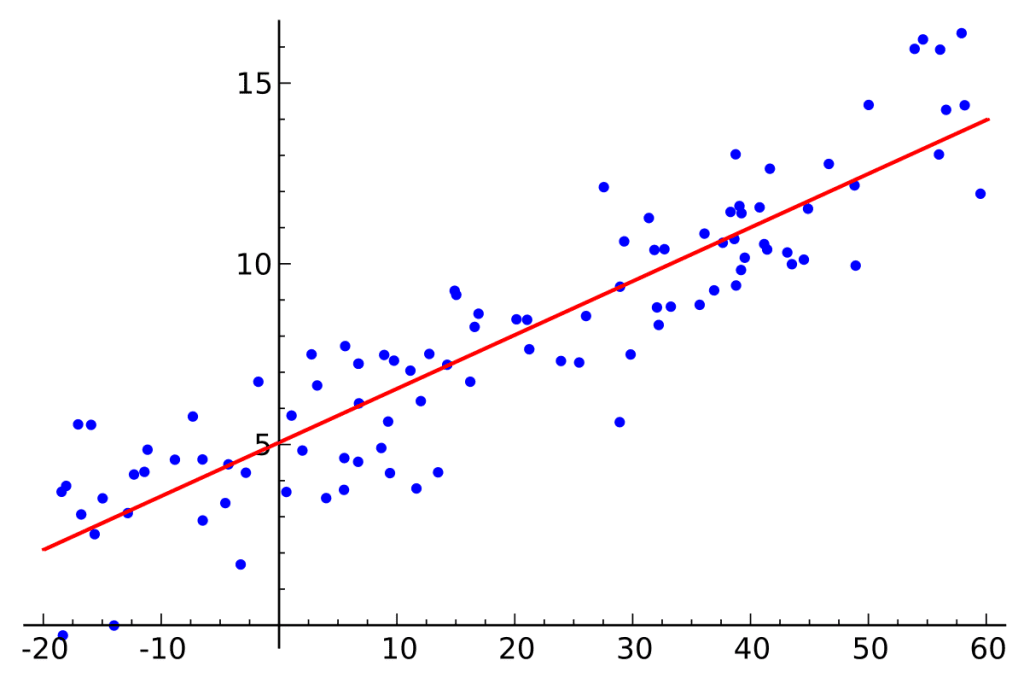
در مدل با اثرات ثابت، شیب رگرسیون (یعنی β ها) در هر مقطع ثابت بوده و عرض از مبدا رگرسیون (یعنی α ها ) از مقطعی به مقطع دیگر متفاوت است.
توجه شود که منظور از مقطع، همان شرکت های بورسی یا کشورها در داده های پانل هستند.
9- مدل با اثرات تصادفی چیست؟
مدل و تصویر درج شده در بخش قبل را در نظر بگیرید:
حال اگر بر خلاف مدل با اثرات ثابت، عرض از مبدا ها (یعنی α ها ) در هر یک از مقاطع مقادیر ثابتی نباشند، بلکه به صورت تصادفی انتخاب شوند و همچنین مستقل از متغیرهای توضیحی (یعنی X ها ) باشند، آنگاه مدل با اثرات تصادفی خواهد بود.
10- آزمون هاسمن برای تشخیص مدل اثر تصادفی از مدل اثر ثابت
رایج ترین آزمون براي تعیین نوع مدل داده هاي (ترکیبی) تلفیقی، آزمون هاسمن است. اگر بعد از انجام دادن آزمونF لیمر فرضیه H0 در مقابل فرضیهH1 رد شده باشد، برای انتخاب بین روش ثابت و تصادفی میتوان از این آزمون استفاده کرد.
به عبارت ديگر در صورتي كه بر اساس نتايج آزمون اف لیمر (چاو) براي هر يك از فرضيه ها، استفاده از روش دادههاي پانل مورد تأييد واقع شود، به منظور اینکه مشخص گردد کدام روش (اثرات ثابت و یا اثرات تصادفی) برای برآورد مناسبتر ميباشد (تشخیص ثابت یا تصادفی بودن تفاوتهای واحدهای مقطعی) از آزمون هاسمن استفاده میشود.
آزمون هاسمن بر پایه وجود یا عدم وجود ارتباط بین خطای رگرسیون تخمین زده شده و متغیرهای مستقل مدل استوار است. اگر چنین ارتباطی وجود داشته باشد، مدل اثر ثابت و اگر این ارتباط وجود نداشته باشد، مدل اثر تصادفی کاربرد خواهد داشت. فرضیه H0 نشان دهنده عدم ارتباط بین متغیرهای مستقل و خطای تخمین و فرضیهH1 نشان دهنده وجود ارتباط است.
به عبارت ديگر، قاعده تصميم گيري آماري به قرار زير است: {برو به فهرست}
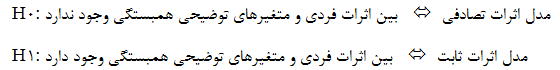
بنابراين عدم رد فرض H0 به معناي وجود مدل با اثرات تصادفي است.
11- آزمون ریشه واحد برای بررسی پایایی متغیرها در پانل دیتا
برای بررسی پایایی یا ایستایی متغیرها در رگرسیون پانل دیتا، از آزمون لوین، لین و چاو (LLC) استفاده می شود. هدف از آزمون پایایی، اطمینان از عدم رخ دادن رگرسیون کاذب می باشد. {برو به فهرست}
ما در خصوص آزمون ریشه واحد یک ویدئوی آموزشی کامل تهیه کرده ایم که از شما دعوت می کنم برای کسب اطلاعات صفر تا صد در خصوص پایایی و ریشه واحد آنرا ببینید: فیلم آموزش پایایی و ریشه واحد در ایویوز
12- نقض فرض نرمال بودن در داده های پانل، رفع خودهمبستگی و ناهمسانی واریانس
در داده های پانل معمولا فرض نرمال بودن باقیمانده های مدل(نرمالیتی) که از فروض اساسی هر رگرسیونی است نقض می شود. این مساله قابل اغماض است. در این خصوص محصولی در فروشگاه این وب سایت موجود است که ابعاد این مساله را به صورت کامل تبیین می نماید. در این محصول شناسایی و رفع سایر فروض کلاسیک رگرسیون از جمله خودهمبستگی سریالی و ناهمسانی واریانس و آزمون عامل تورم واریانس (VIF)، در داده های پانل بررسی و راهکار ارائه می شود: تحلیل رگرسیون و بررسی نیکویی برازش
13- پانل دیتا در پایان نامه ها و مقالات
با توجه به مزایایی که بر شمردیم، شاهد آن هستیم که هم اکنون در بسیاری از پایان نامه های دانشجویی رشته های مرتبط با اقتصاد در کشورمان از داده های پانل استفاده می شود. همین وضعیت را در خصوص مقالات معتبر و ISI نیز می بینیم. {برو به فهرست}
البته یکی از علت های دیگر فراگیر بودن استفاده از پانل دیتا در تحقیقات اقتصادی کشور، این است که منبع غنی ای از داده های در دسترس، که به صورت پانل هستند، در بازار بورس اوراق بهادار موجود است. بورس جایی است که اطلاعات شرکتها در آن با شفافیت بسیار بیشتری نسبت به سایر شرکتهای فعال در کشور قابل دسترسی است.
14- تحلیل پانل دیتا با eviews
در نرم افزار ایویوز نیز پانل دیتا به خوبی تعبیه شده است. البته تعریف داده ها به صورت پانل برای نرم افزار eviews ظرافت کاریهایی دارد که ما در این خصوص نیز محصولی در فروشگاه این سایت عرضه نموده ایم. لینک این محصول در انتهای این مقاله موجود است.
چنانچه نرم افزار ای ویوز داده ها را به صورت پانل شناسایی نکند، امکان انجام آزمون های لازم بر روی آنها وجود ندارد.
1-14- قبول سفارش تحلیل پانل دیتا (فصل 4 پایان نامه) با ایویوز 9
این مجموعه تخصصی آماری آمادگی انجام تجزیه و تحلیل داده های پانل یا ترکیبی را در نرم افزار ایویوز دارد (البته لازم است داده ها به صورت کامل جمع آوری شده باشند). در این تحلیل آزمون ها و روشهای اقتصاد سنجی و آماری بر روی داده ها انجام و فرضیات پایان نامه آزمون می گردد. برخی از آزمون هایی که در تحلیل فصل 4 پایان نامه با ایویوز مورد استفاده قرار می گیرد به قرار زیر است:
- محاسبه آماره های توصیفی و نمودارهای توصیفی متغیرها
- آزمون ریشه واحد (بررسی مانایی)
- آزمون هم انباشتگی (هم جمعی)
- بررسی هم خطی بین متغیرهای مستقل مدل
- بررسی مدل تجمیعی یا پانل (pooled or panel)
- آزمون اف لیمر (چاو)
- آزمون هاسمن
- برآورد مدل رگرسیون
- آزمون نرمال بودن باقیمانده های مدل
- آزمون همخطی متغیرهای مستقل (معیار عامل تورم واریانس – آزمون VIF)
- آزمون ناهمسانی واریانس (آزمون وایت)
- آزمون خود همبستگی بین باقیمانده های مدل
برای سفارش تحلیل با ما ارتباط بگیرید. ضمنا چنانچه مایلید شرح و توضیحات هر کدام از آزمون های فوق را بدست آورید و به عنوان فصل سوم (روش تحقیق) در پایان نامه خود به کار بگیرید، این صفحه را ملاحظه نمایید:
2-14- مشاوره سوالات پانل دیتا
هر گونه سوالی در خصوص داده های پانل دارید، در پایین همین صفحه و در بخش دیدگاه درج نمایید. در اولین فرصت پاسخ آنرا خواهیم داد.
3-14- آموزش ورود داده های پانل به EViews
در بخش فروشگاه این وب سایت می توانید محصول آموزشی ما با عنوان نحوه ورود و تعریف داده های پانل به EViews را، که در قالب دستورالعملی تصویری ساخت داده های پانل در ایویوز را آموزش می دهد، دریافت نمایید:
4-14- نمونه فصل 4 پایان نامه پنل دیتا
با مراجعه به آدرس زیر می توانید نمونه استاندارد و بهینه فصل 4 پایان نامه که با نرم افزار ایویوز تجزیه و تحلیل شده است را دریافت دارید (فایل ورد). فیلم تشریح نتایج و آزمون های آماری و اقتصاد سنجی انجام شده نیز در این محصول گنجانده شده است:
5-14- نمونه فصل 3 پایان نامه پنل دیتا (روش تحقیق پانل دیتا)
در صورتی که در حال نگارش پایان نامه پانل دیتای خود هستید، اصلا در خریداری این محصول شک نکنید! شرح کامل آزمون ها و روش تحقیق مدل رگرسیون پانل دیتا (داده های تابلویی) را با خریداری این محصول بدست خواهید آورد. در صورت تمایل فیلم تشریح این آزمونها را نیز می توانید دریافت نموده و با مفاهیم اقتصاد سنجی پایان نامه خود آشنایی کامل بدست آورید:





باسلام مطلب پنل دیتا که ارائه کردید عالی بود
با تشکر
خواستم ببینم پنل دیتا پیش فرض دارد ؟
ارزیابی نرما بودن توزیع متغیره و …
لطفا میشه راهنمایی بفرماییید
سلام. خواهش.
اینکه داده ها به صورت پانلی باشند نیاز به هیچ پیش فرض خاصی ندارد. همینکه دو بعد داشته باشند، پانل (تابلویی یا ترکیبی) هستند.
البته توجه داشته باشید که در رگرسیونی که با داده های پانلی برآورد می شود، ارزیابی نرمال بودن یک موردی است که معمولا مشاهده می شود باقیمانده ها نرمال نیستند. اما این جای نگرانی ندارد. توضیحات این محصول را ببینید با کلیک بر روی: فروض اساسی رگرسیون در داده های پانل (ترکیبی)
یا این بسته آموزشی ویدئویی را دریافت نمایید که من باب بررسی نیکویی برازش خیالتان راحت باشد:
https://www.eviews-iran.ir/product/analysis-goodness-of-fit/
باسلام
برای تبیین علیت متغیرها در مدل پنل چه راهکاری وجود دارد؟ ممنون از راهنمایی شما
سلام
علیت متغیرها در نرم افزار ایویوز و اقتصاد سنجی با آزمونی به نام آزمون “علیت گرانجر” بررسی می شود. که در داده های پنلی نیز همانند داده های سری زمانی یا مقطعی قابل انجام است. نکته مهم این است که قبل از انجام آزمون علیت از مانا بودن متغیرها اطمینان حاصل کرد.
سلام
چگونه از داده های مقطعی داده شبه پنل بسازم؟
سلام؛ منظورتان از داده های شبه پنل نمی دانم چیست، اما در حالت کلی، اگر بخواهید داده های مقطعی را به داده های پانل تبدیل نمایید لازم است این داده ها را به ازای زمان های مختلف جمع آوری نمایید تا یک بعد دیگر که همان بعد زمان است نیز به داده هایتان بدهید و آنها را به داده های پنل تبدیل نمایید.
مثلا اگر اطلاعات شرکتهای بیمه را برای مقطع (سال) 94 دارید، همین اطلاعات را برای سالهای 95 و 96 و 97 نیز جمع آوری کنید تا داده های پنلی داشته باشید. بدین ترتیب می توانید یک مدل را با تعداد داده خیلی بیشتری اجرا کنید!
با سلام و احترام. امکان برآورد مدل VAR در داده های پانلی هست؟
سلام؛ تا جایی که من کار کرده ام و می دانم در نرم افزار ایویوز تا نسخه 9.5 این امکان وجود ندارد که مدل var را در داده های پانلی کار کرد.
لطفا دوستان دیگر نیز اعلام نظر داشته باشند تا به پاسخی قطعی برسیم
امکان برآورد مدل var در داده های پانلی موجود است که به آن panel var گفته می شود و از طریق نرم افزار stata ورژن 14 به بعد امکان برآورد آن موجود است
با سلام
پایان نامه اینجانب به صورت پانل دیتا می باشد و با خرید تمام محصولات اطمینان شرق فصل 3 و 4 پایان نامه خود را نوشتم اما استاد راهنمایم تاکید دارند تا برای تک تک کشورها(مقطع ها) هم به دست آید نمی دانستم که چگونه برای تک تک هم در ایویوز انجام دهم لطفا جواب من را بدهید که چگونه برای تک تک کشورها هم به دست آورم.
سلام؛ با تشکر از خرید شما. امیدوارم راهگشا بوده باشد. ما برای تهیه نمونه فصل 3 و 4 پانل دیتا زحمت زیادی کشیده ایم و سعی کردیم همه موارد را در آن بگنجانیم تا دانشجو خود بتواند این فصول اساسی پایان نامه اش را بنویسد.
در خصوص سوال شما: اگر قرار باشد به ازای هر کشور رگرسیون را انجام دهید، عملا دیگر روش پانل دیتا نخواهد بود و داده های شما تبدیل به داده های سری زمانی به ازای هر کشور می شوند. خیلی کار وقت گیری خواهد شد. احتمالا منظور استاد خوب منعکس نشده است.
شاید منظور استاد این است که اگر شما به مدل اثرات ثابت یا اثرات تصادفی رسیده اید، میزان این اثرات را به ازای هر کشور (مقطع) نیز گزارش نمایید. برای این کار کافیست بعد از ران کردن مدل، در منوی view، گزینه fixed/random effects را بزنید تا اثرات ثابت یا تصادفی را به ازای هر کشور به شما اعلام نماید.
سلام جناب فرشچی ارجمند
وقت بخیر
بعد از ران مدل به روش اثرات تصادفی، زمانیکه پسماند را بررسی می کنم نرمال نیستند. همچنین همسانی واریانس هم ندارند. قبلا اگر اثرات ثابت بود می توانستم با اضافه کردن ar مشکل ناهمسانی را برطرف کنم. اما حال که اثرات تصادفی است و پسماند نه نرمال است و نه همسانی واریانس دارد چه عملی باید صورت گیرد؟
سلام؛ اوقات شما نیز بخیر
چند نکته در خصوص صحبت های شما وجود دارد. اول اینکه وقتی داده ها پانل هستند، لزوما نباید دارای توزیع نرمال باشند و قابل اغماض است این مساله. در این خصوص محصول زیر را بررسی و خریداری نمایید:
https://www.eviews-iran.ir/product/normality/
برای رفع ناهمسانی واریانس نیز اضافه کردن AR راه حل نیست. بلکه می بایست اقدامات دیگری انجام دهید که آن نیز اتفاقا در محصول فوق گفته شده است.
شاید منظورتان رفع خودهمبستگی سریالی بین باقیمانده بوده که برای این مساله نیز در محصول فوق صحبت شده.
قصدم فقط تبلیغات کردن برای فروش محصول نبود اما همه چیز ختم به آن شد! بهرحال اینجا مجال نیست روش حل مشکل را توضیح داد و فقط می شود آدرس کلید را داد.
اگر آموزش ویدئویی موارد فوق را بخواهید ببینید که به تسلط کامل برسید این بسته آموزشی:
https://www.eviews-iran.ir/product/analysis-goodness-of-fit/
سلام خدمت شما آقای فرشچی عزیز
محصول را قبلا تهیه کرده بودم. اما در خط آخر گفته شده این روش برای تخمین random فعال نخواهد بود.
سلام و ارادت
این نکته در خط آخر گفته شده اگر مدل با اثرات تصادفی باشد، گزینه weights فعال نیست که همین طور هم هست. اما خوب بهرحال گزینه coef covariance method همچنان فعال است و با کمک آن می توانید اثر ناهمسانی واریانس را خنثی نمایید.
با عرض سلام
ببخشید وقتی آزمون اف لیمر تعیین کرد که داده ها از نوع پولد هستند نیازی به آزمون هاسمن نیست؟ و اینکه ادامه برآورد مدل رو به چه صورت باید انجام داد؟ و چه آزمون های دیگری رو باید انجام داد؟ ممنون میشم سریع جواب بدین
سلام؛ وقتی معلوم شد پولد هستند و فاقد اثرات ثابت یا تصادفی هستند، دیگر نیازی به آزمون هاسمن نیست.
اگر اینطور بود، کافی است مدل را بدون هیچ گونه اثرات ثابت یا تصادفی برآورد کنید و فرضیات را آزمون کنید. کار بعدی تعیین شاخص های برازش مدل است.
برای تشخیص مدل پولد از مدل دارای اثرات و شناخت کامل هاسمن و اف لیمر، این بسته آموزشی به صورت اختصاصی تهیه شده است:
https://www.eviews-iran.ir/product/f-limer-hausman/
با سلام خدمت جناب آقای فرشچی و تیم بسیار قوی شما
اولا تشکر بابت مطالب ارزنده و فاخر و نشر آن به مصداق حدیث “زکات دانش نشر آن است”
ثانیا به دلیل اینکه بنده در حال نوشتن فصل 4 رسالۀ دکترای خود هستم چند سوال کلیدی دارم که خواهش میکنم همین جا جوابش رو بدید:
1- آیا امکان تحلیل آماری برای متغیرهایی که از نوع سال و شرکت(پانل) و متغیرهایی که تنها برای چند سال بررسی می شوند(سری زمانی) به طور همزمان از طریق رگرسیون وجود دارد؟
2- بهترین روش آماری برای این نوع دیتاها و این نوع متغیرها چه روشی است؟
3- آیا از لحاظ آماری اگر داده های سال و شرکت به داده مقطعی(یعنی یک عدد در یک سال) تبدیل شوند یعنی مثلا از داده های کل شرکتها در یک سال معین میانگین گرفته شود و سپس در طول یک بازه زمانی(سری زمانی) همراه با سایر داده هایی که ذاتا از نوع سری زمانی هستند مورد بررسی قرار گیرند اشکال و ایرادی در تحلیل چنین داده هایی برای انجام رگرسیون به وجود می آید؟
4- اگر متغیر وابسته ما با چند پیروکسی(شاخص) اندازه گیری شود در رگرسیون چگونه می توانیم آنرا مورد تحلیل قرار دهیم؟
5- اگر بین متغیرهای مستقل و وابسته یک سری روابط برقرار باشد(معادله ساختاری) و هر کدام با چند پیروکسی(شاخص) مورد اندازه گیری قرار گیرند آیا بهترین روش و تنهاترین روش استفاده از روش مدل معادله ساختاری(sem) است؟
6- اگر در مدل معادلات ساختاری در نرم افزار smartpls آزمون معنی داری z (t value) ران نشود مشکل کار از کجا می باشد؟
7- اگر در مدل معادله ساختاری بعضی از متغیرها معنی دار نشوند(مثلا در سطح 10%) روشی برای رفع این مشکل وجود دارد؟
بسیار سپاسگزار میشوم اگر همین جا به سوالات جواب دهید. شاید سوال خیلی از دانشجویان و پژوهشگران باشد. ارادتمند..
سلام، خواهش.
جواب سوال 1: عملا خیر. شما می توانید تحلیل آماری را برای داده های پانل انجام دهید، اما اینکه بیایید اطلاعاتی که برای چندین شرکت آماده کردید به کنار بگذارید و فقط روی یک شرکت برای مثلا 6 سال کار کنید، منطقی نیست. از طرف دیگر برای بررسی سری زمانی حداقل باید اطلاعات 20 سال را داشته باشید که بعید می دانم داده های پانل شما اینطوری باشد.
جواب سوال 2: قطعا بهترین روش همان پانل دیتا است که از همه این داده های شرکتها و سالهای مختلف استفاده می کند.
جواب سوال 3: این حرکت مثل این می ماند که اطلاعات ارزشمند خود را عصاره گیری کرده و به دور بریزید. وقتی اطلاعات بیشتری دارید و ساز و کار استفاده از آن را هم دارید (رگرسیون پانل دیتا) باید استفاده کرد. مثل سوال 1 (از جنبه دیگر) این کار صحیح به نظر نمی رسد. مگر اینکه مدل مد نظر شما خیلی خاص باشد.
جواب سوال 4: در یک رگرسیون یک متغیر وابسته بیشتر نداریم. مگر اینکه چند مدل رگرسیون تعریف کنید که متغیرهای وابسته آن با هم تفاوت کنند اما متغیرهای سمت راست مدل یکی باشند.
جواب سوال ۵: بله
جواب سوال ۶: یا مشکل از داده است یا مدل بزرگ و حجم نمونه مناسب نیست.
جواب سوال ۷: یک راه حل این هست که مجدد داده جمع آوری شود شاید جواب بهتری گرفت.
سلام
اگر تعدادی از داده ها مانا باشند وتعدادی هم نامانا، و با یکبار تفاضل گیری مانا شوند، برای استفاده از پانل دیتا بخواهیم روش (PMG ،(ARDL را استفاده کنیم،
1) آیا باید داده های نامانا را مانا کرد؟
2)اگر روش panel باشد و نه pool از این متد می شود استفاده کرد؟
3) برای این متد نیازی به بررسی آزمون اثرات ثابت و هاسمن هست؟
سلام. مطمئن هستید که داده های پانل شما مانا نیستند؟ توجه داشته باشید که مانایی گزینه های متنوعی دارد و قلق های خاص خودش را در نرم افزار ایویوز. اگر فکر می کنید اطلاعات بیشتری در خصوص مانایی نیاز دارید در منو محصولات آموزش ویدئویی ریشه واحد را دریافت نمایید.
وقتی داده ها پانل هستند دیگر روش آردل را نمی شود اجرا کرد. یا آردل یا پانل دیتا.
بله از متدهای اموزشی استفاده کردم.
پیش شرط استاده از PMG چیست؟
سلام سپاس ازحوصله وپاسخ گویی حضدتعالی
بزرگواری بفرمائیدوپاسخ این سوال رابفرمائید فکرکنم جوابی به این سوال نداد
۱) آیا باید داده های نامانا را مانا کرد؟
یک سوال دیگر اگرپاسخ دهیدسپاسگذار خواهم بود
آیامانابودن متغیرهای باینری 0 و1 راهم بایدبررسی نمود؟
سلام
1- نه لزوما. در داده های پانل در صورتی که آزمون هم انباشتگی تایید شود، می توان از نامانا بودن یک متغیر اغماض کرد. گاهی نیز با بررسی و حذف داده های پرت، متغیر مانا می شود.
2- بله. آنها را نیز بایستی بررسی کنید. می تواند مانایی شان تایید یا رد شود.
سلام مطالب را با زبان ساده بسیار عالی و قابل فهم بیان میکنید .متشکریم استفاده زیادی بردیم
سلام ببخشید من وقتی میخوام داده های پنلو وارد کنم نمیشه این گزینه میادcell can not be edited
سلام. برای اینکه بتوانید ویرایش کنید داده ها را در ایویوز، بر روی آیکن + – لازمه کلیک کنید. احتمالا از این باشد خطا.
در جریان باشید که در منو محصولات این وب سایت می توانید آموزش ویدئویی نحوه ورود داده های پانل به ایویوز را تهیه کنین. از این لینک:
https://www.eviews-iran.ir/product/panel-import/
این اولین خشت کار با ایویوز است . . .
سلام
من داده هام بصورت پانل هست. مدل رگرسیونم خطی نیست به این صورت هست
LEVt = α1ECRt−1 + α2ECR2 t−1 + α3CFRt−1 + α4CFR2 t−1 + α5QRRt−1 + α6QRR2 t−1 +α7DIVt−1
داده هایی که بتوان دو هست رو چطوری میتونم وارد کنم؟
سلام. در خصوص رگرسیون غیر خطی اطلاعاتی نداریم.
دوستان دیگر لطفا اعلام نظر نمایند.
سلام اولا در ساختن مدل ایراد وجود دارد زیرا معمولا وقفه متغیر مستقل زمانی وارد می شود که متغیر به صورت همزمان وارد الگو شده باشد (اگر منظورتان از مدل ARDL پنلی است) ثانیا این الگو اصلا غیرخطی نیست (از نظر پارامترها) که ناچار به تخمین زن غیرخطی باشید ثالثا نمی دانم منظور از اینکه نمی توانم متغیرهای درجه دوم را وارد کنم چیست ورود آنها همانگونه انجام می گیرد که درجه اول انجام می شود رابعا مشکل اصلی این مدل احتمال نقض فروض کلاسیکها است که باید با انتخاب تخمین زن مناسب آن را رفع کرد
سلام
اگر داده ها از ابتدا بصورت pool وارد کنیم چه آزمون هایی باید انجام بدیم؟
سلام. توجه شود که پنل یا پول بودن داده ها را بعد از آزمون اف لیمر می توان تشخیص داد.
ولی در حالت کلی وقتی داده ها به صورت pool (پول) وارد شده اند، آزمون های رگرسیون معمولی را باید انجام داد: مانایی، عدم خود همبستگی، عدم هم خطی، نرمال بودن باقیمانده ها، مدل رگرسیون، . . .
سلام
آیا داده های پانلی(ترکیبی) نیاز به انجام آزمون ناهمسانی واریانس دارند؟
سلام. بله بهتر است انجام شود. بعد از اینکه متوجه شدیم ناهمسانی واریانس داریم می توانیم با تغییراتی در گزینه ها پنجره مدل در نرم افزار ایویوز، تعدیل لازم را اعمال کنیم. در قالب و نمونه فصل 4 پایان نامه که در منو محصولات این وب سایت است این کار را انجام داده ایم و تحلیلش هست. البته آموزش انجام این کار را از این بسته آموزش ویدئویی دریافت نمایید:
https://www.eviews-iran.ir/product/analysis-goodness-of-fit/
با سلام برای بررسی پنل دیتا در استاتا چند سال بررسی کافیه؟ ایا با بررسی پنج سال میتونیم بررسی رو انجام بدیم یا دوره زمانی کوتاه هست؟
سلام. اینکه نرم افزار استتا باشد یا ایویوز از این نظر فرقی ندارد: بله، با 5 سال هم می شود داده های پانل را تحلیل کرد. به شرط آنکه تعداد شرکتها (مقاطع) نسبتا زیاد باشد.
سلام
اگر بخواهیم پانل نامتوازن انجام دهیم باید چیکار کنیم؟
سلام. اگر منظور از پانل نامتوازن این است که در ماتریس داده های خود، مواردی از داده های گمشده داشته باشیم (پانل کامل نباشد)، تفاوت خاصی در شیوه کار وجود ندارد.
سایر دوستان اگر اطلاعات بیشتری دارند اعلام نظر نمایند.
استادم به من گفتن چون پانل کامل نیست باید از روش پانل نامتوازن استفاده کنید و در منو به جای balanced شما ازunbalanced استفاده کنید … حالا من نمیدونم این منو کجاست؟
این مساله ورود داده به صورت balanced یا pool در فصل اول کتاب ایویوز دکتر افلاطونی آمده است. اما به نظر من فقط کار ورود داده را برای دانشجو بسیار سخت کرده است و گیج کننده. در نتیجه کار و در خروجی گرفتن و کار با نرم افزار ایویوز هم هیچ فرقی نمی کند که چطور داده وارد شود.
از قول اینجانب از استاد محترم بپرسید که در ( نتیجه و خروجی کار چه فرقی می کند که داده ها از کدام روش وارد شود؟ )
مهم این است که داده ها به صورت پانل و به درستی به نرم افزار معرفی شود و خروجی ها گرفته شود. در بسته آموزش ویدئویی “ورود داده به ایویوز” که در منو محصولات گذاشته ایم، هدف همین ساده کردن کار و ورود راحت از اکسل به ایویوز است. لینک این بسته آموزشی:
https://www.eviews-iran.ir/product/panel-import/
سلام وقت بخیر
در رابطه با تحلیل آمار توصیفی متغیرها از کجا میتونم کمک بگیرم؟
ممنونم
سلام. با ایویوز آمارهای توصیفی را می توان استخراج نمود. این بسته آموزش ویدئویی مساله شما را حل می کند:
https://www.eviews-iran.ir/product/normality-descriptive/
سلام
میخواستم بدونم در مدل ضرایب با و بدون متغیرهای کنترل چه تغییری می کنن انتظار میره وقتی متغیر کنترل وارد بشه ضریب متغیر وابسه چجور بشه؟
سلام. قاعدتا با ورود متغیرهای کنترل به مدل، ضرایب سایر متغیرها نیز تغییر می کنند و ممکن است متغیری که معنی دار بوده از معنی داری خارج شود و یا بالعکس. ضریب تعیین نیز افزایش خواهد یافت با ورود متغیر کنترل جدید.
با سلام
با تشكر از مطالب مفيد سايت شما
من براي پايان نامه 3 مدل رگرسيوني دارم كه اين مدل ها با روش GMM در نرم افزار Eviews برآورد شده اند.
مشكل بنده با آماره t محاسبه شده در هر يك از خروجي هاي نرم افزار براي اين 3 مدل است.
به صورت تعريف، آماره t عبارت است از حاصل تقسيم ضريب بر انحراف استاندارد ضريب مربوطه.
اما در خروجي هاي نرم افزار اين ارتباط وجود ندارد. يعني آماره t محاسبه شده در جدول با حاصل تقسيم ضريب بر انحراف استاندارد، برابر نيست. دليل اين امر چيست؟؟
سلام. روش GMM از روشهای بسیار پیچیده اقتصاد سنجی است که تا جایی که من می دانم در منابع فارسی شرح کاملی از آن نیامده است. شیوه محاسبه آماره تی در این روش به نظر پیچیده است.
سلام.
ممنون از پاسخ شما.
یعنی فرمول عادیه آماره t در روش GMM کاربرد ندارد؟؟
جایی هست که توضیح آماره t برای این روش رو ارائه کرده باشه؟ اگر امکانش هست لطفا در این زمینه راهنمایی بیشتر بفرمایید. ممنون میشم.
سلام. اطلاع دقیقی ندارم. منبع در خصوص روش GMM بسیار کم است. اگر سایر دوستان منبعی سراغ دارند اعلام نمایند.
ممنون از توجه و پاسخ شما
سلام متغیر وابسته من به صورت صفر و یک تعریف شده در واقع یک متغیر کیفی هست. باید از رگرسیون لجستیک استفاده کنم ؟ و اینکه در فایل های آموزشی شما این نوع رگرسیون هم توضیح داده شده؟
سلام. بله باید از رگرسیون لجستیک استفاده نمایید.
در بین محصولات آموزشی موجود در سایت، با توجه به موضوعشان، فرقی نمی کند متغیر وابسته صفر و یک باشد یا غیر از آن و برای شما نیز قابل استفاده است.
البته با توجه به عناوین آموزش ها، مشخصا رگرسیون لجستیک آموزش داده نشده است.
سلام
اگه آزمون f انجام شد و پول دیتا پذبرفته شد، میتوانیم از مدل pmg استفاده کرده و مدل را ران کرد؟
سلام. مدل pmg کار نکردم و نمیدانم چیست.
با سلام و خسته نباشید آیا آزمون شکست ساختاری برای داده های پانل همان آزمون چاو می باشد؟ اگر بله لطفا مسیر آنرا در نرم افزار ایویوز مشخص کنید
سلام. شکست ساختاری برای داده های سری زمانی معمولا استفاده می شود نه پانل دیتا. در جریان نیستم.
سلام
در مدل پانل برای نشان دادن عرض از مبدا ها از چه مسیری باید رفت؟
سلام. اگر منظورتان در مدل با اثرات ثابت یا تصادفی، دیدن مقادیر اثرات است، در منوی view به عنوان fixed effect کلیک کنید این مقادیر داده می شود. اگر این مقادیر را نمی توانید بیابید ممکن است داده ها را به عنوان پنل به نرم افزار نشناسانده باشید.
از بسته های آموزش ویدئویی ما برای اینکه بتوانید به خوبی با نرم افزار کار کنید بهره ببرید.
سلام
تابع عرضه و تقاضا رو با پانل تخمین زدم حالا شیب تابع رو لازم دارم چطوری شیب رو بدست بیارم؟
سلام. دقیقا منظور شما از شیب را متوجه نشدم. اما در یک معادله خطی، شیب همان ضریب متغیر مستقل است. بنابراین احتمالا شیب تابع از روی ضرایب متغیرها بدست می آید. سایر دوستان نیز اعلام نظر داشته باشند
با سلام خدمت آقای فرشچی
موضوع پایان نامه من در مورد نوسانات تجارت و تاثیر آن بر اقتصاد داخلی کشور های اسلامی است.ممنون میشم اگر در مورد آزمون مناسب این موضوع و همچنین مدل متناسب با آن رهنماییم کنید.با تشکر
با سلام . میشه مسیر انجام آزمون اف لیمر در ایویوز رو بگین ممنون
سلام. اصل سختی کار پانل دیتا همین تشخیص مدل با اثرات ثابت یا مدل با اثرات تصادفی است. و با نشان دادن مسیر آزمون اف لیمر حل نمی شود.
این بسته آموزش ویدئویی را دریافت نمایید تا به خوبی به مقصود برسید:
https://www.eviews-iran.ir/product/f-limer-hausman/
سلام
من روشم پنل پویا است آیا لازمه اف لیمر و یا هاسمن هم آزمون کنم
ممنون
سلام. بله در پنل پویا هم لازمه تشخیص داده شود مدل با اثرات ثابت است یا تصادفی. و به آزمون های اف لیمر و هاسمن نیاز است.
آزمون اف لیمر کلا برای تشخیص این است که داده ها پنل است یا پولد.
این بسته آموزشی ویدئویی را تهیه نمایید: https://www.eviews-iran.ir/product/f-limer-hausman/
با سلام و خسته نباشید.بنده یه سوال داشتم و اینکه در ازمون چاو وقتی مدل اثرات ثابت پذیرفته شد و ازمون هاسمن رو انجام دادیم ایا حتما باید ازمون هاسمن هم فرض صفر رو رد کنه که اثرات ثابت تایید بشه ؟و یا اینکه مشکلی ایجاد نمیشه اگه هاسمن اثرات تصادفی رو تایید کنه؟
سلام. دقت کنید که آزمون چاو برای تعیین اثرات ثابت یا تصادفی نیست. بلکه برای تعیین و تفکیک مدل پانل از مدل پولد است.
اگر مدل پانل بود، آنگاه این آزمون هاسمن است که مشخص می کند مدل پانل با اثرات ثابت است یا تصادفی.
این بسته آموزشی ویدئویی را تهیه نمایید: https://www.eviews-iran.ir/product/f-limer-hausman/
با سلام
ممنون از این همه لطف و وقتی که بابت پاسخگویی میزارین ،
چند سوال دارم :
1)داههای من از نوع پانل هستند،نتایج آزمون f-لیمر نشان میدهد که عرض از مبدا در تمامی مقاطع یکسان است(دادهها تلفیقی) با این حساب برای بررسی خودهمبستگی و ناهمسانی واریانس از کدام آزمونها استفاده کنم بهتر و کاراتر است؟(اسم آزمون لطفا)
2)با توجه به تلفیقی بودن دادهها اگه مشکل خودهمبستگی و ناهمسانی واریانس وجود داشت از چه روشی رفعشون کنم؟
3)اگر تعدادی از متغیرهام نامانا باشند باید چیکار کنم؟
و در آخر تشکر و معذرت بابت سوالات زیاد.
سلام. 1- برای بررسی خودهمبستگی از روش تعریف رگرسیون بر روی باقیمانده ها استفاده می شود و آماره آزمون فیشر آن دستی محاسبه می شود. برای ناهمسانی واریانس هم آزمون وایت استفاده می شود. 2- رفع این موارد مفصل است، در انتهای همین متن خواهم گفت. 3- با بررسی گزینه ها و آزمونهای مختلف مانایی سعی کنید به مانایی آن متغیرها برسید (در منو محصولات آموزش ویدئویی شیوه کامل آزمون ریشه واحد آمده است) و اگر نشد، حذف داده های پرت را بررسی کنید.
آموزش نحوه برخورد با داده های پرت: https://www.eviews-iran.ir/product/outlier/
اما اینکه دقیقا چطور در داده های پانل، خودهمبستگی و ناهمسانی واریانس را بررسی و رفع کنید، این بسته آموزشی ویدئویی را تهیه نمایید: https://www.eviews-iran.ir/product/f-limer-hausman/
ببخشید یه سوال دیگه از بین آزمونها جهت برسی مانایی(شامل لوین,لین و چو ، ایم ,پسران وشین ،دیکلی-فولر تعمیم یافته ، فیلیپس پرون، بریتانگ، هادری) کدومشون مناسبتره زمانی که دادهها از نوع پانل با 22 مقطع و 4 سال باشه؟
مثلا آزمون لین، لوین- چو :لازمه کارایی این آزمون این است که N نسبت به T کوچک باشد. ولی دادههای من اینجوری نیست.
آزمون ایم- پسران- شین:این آزمون نیز خاص پنل های نامتوازن بوده ،نمیدونم از کدوم آزمون باید استفاده کنم.
حالا اگه آزمون نشان بده که تعددی از متغیرها نامانا هستند، برای رفع این مشکل چیکار باید کرد؟(جایی خوندم که برای رفع این مشکل باید از تفاضل استفاده کرد؛یعنی چی دقیقا باید چیکار کنم؟)
هر کدام که مانایی متغیرهای شما را نشان بدهد به نظر من خوب است. زیاد سخت نگیرید. با گزینه های مختلف عرض از مبدا و روند حالتهای مختلف را امتحان تا مانا شود.
اگر واقعا یک متغیری دیگه هیچ راهی نداشت اینطوری تفاضل بگیرید: داده هر سال را از داده سال قبل آن کسر کنید و آنرا به عنوان داده جدید درج نمایید. قاعدتا با این کار داده اول را از دست می دهید.
سلام برای تشخیص نوع داده ها از نظر پنل (ترکیبی) و پول (تلفیقی) باید ازمون لیمر انجام بدیم که اگر پراب آن کمتر از 0.05 بود داده ها پول هستن درسته ؟ حالا که داده ها پول هستن باید آزمون هاسمن رو برای مشخص کردن نوع تخمین داده ها از نظر اثرات ثابت و تصادفی انجام بدم ؟ اگه پراب از 0.1 کمتر باشه مدل اثرات ثابت است؟
سلام. بخش اول را درست گفتید.
اما اگر داده ها پول بودند و پانل نبودند، دیگر نیازی به آزمون هاسمن نیست. برای اینکه وقتی پول است دیگر مدل با اثرات ثابت یا تصادفی معنایی ندارد. اثر ثابت یا تصادفی مربوط به مدل پانل است.
وقتی مدل پول است، بدون هیچ اثراتی مدل رگرسیون را ران کنید.
این بسته آموزشی ویدئویی را تهیه نمایید: https://www.eviews-iran.ir/product/f-limer-hausman/
با سلام
اگر داده های من دو بعد داشته باشن نمیتونم از رگرسیون لجستیک استفاده کنم ؟حتما باید از پنل دیتا استفاده کرد؟
سلام. می توانید هم پانل دیتا داشته باشید و هم رگرسیون لجستیک را پیاده کنید. نسخه ایویوز شما 9 به بالا باشد.
لطفا یه نفر الگوی اثرات ثابت رو برام توضیح بده فردا دفاع دارم؟
این بسته آموزشی ویدئویی را تهیه نمایید. کامل مدل با اثرات ثابت و تصادفی هم از نظر تئوری گفته شده و هم کار با ایویوز با داده ها انجام شده است:
https://www.eviews-iran.ir/product/f-limer-hausman/
سلام وقت شما بخیر–با تشکر از شما بابت آموزش های کامل و بسیار عالی که تهیه کردید.
در انجام پروژه دانشجویی خودم با مدلی سر و کار دارند که متغیرهای موجود در آن هم به صورت سری زمانی و هم پانل دیتا می باشد به طور مثال تورم ایران طی ده سال گذشته که به عنوان داده های سری زمانی مورد استفاده قرار میگیرد در کنار آن داده دیگری به صورت پانل هم وجود دارد. به طور مثال میزان سود ویژه ۵ بانک کشور در همین بازه زمانی را هم بایستی وارد مدل کنم، حالا سوال بنده این است که برای تخمین زدن مدل و استفاده کردن از این دو نوع داده به چه صورت بایستی عمل کنم چون هم داده های سری زمانی و هم داده های پانل دیتا موجود است؟
سلام, خواهش.
دو نوع داده سری زمانی و پانل در یک مدل قابل بررسی و برازش نیستند و حتما باید داده ها به یک فرمت تبدیل شوند. یا همه سری زمانی یا همه داده ها پانل شوند.
احتمالا شما باید با توجه به نام شرکتها، اطلاعات سری زمانی مثل نرخ تورم را تکرار کنید. بدین ترتیب که به ازای هر شرکت بورسی، نرخ تورم به ازای سالهای مختلف درج شود.
ضمنا اگر در زمینه ورود داده به ایویوز سوال داشتید، محصول آموزش ورود داده از اکسل به ایویوز را تهیه نمایید:
https://www.eviews-iran.ir/product/panel-import/
برای برآورد آستانه بهینه پنل در ایویوز باید چکار کرد ؟
با سلام تشکر از آموزشهای کاربردیتان. چند سوال از خدمتتان داشتم.
داده های پرت را در نرم افزار eviews حذف کردم اما باز هم متغیرها معنی دار نیستند و ضریب تعیین بسیار پایین است مشکل از چیست؟
فرضیه های پایان نامه من دارای متغیر میانجی است که باید از روش بارون و کنی استفاده شود که بارون کنی دارای چند پیش شرط است که باید مدلهایی طراحی شود. سوالم این است که امکان دارد بعضی مدلها پول و بعضی پانل شوند؟
زمانی که مشخص شد مدل از نوع پول است برای تخمین مدل اصلی باید در قسمتpanel option قسمت مکانی و زمانی هردو باید none باشند و نیاز به تغیر دیگری نیست؟برای اثرات ثابت چطور؟
برای بررسی همسانی واریانس در مدل پول زمانی که مسیر آزمون Whit را طی می کنم خطایی با عنوان نزدیک به ماتریس واحد را می دهد.مشکل از کجاست؟
سلام. خواهش.
1-همیشه با حذف داده های پرت متغیرها معنی دار نمی شوند. بهرحال اکثر اوقات داده ها روابطی قطعی دارند که در هر شرایطی آن را حفظ می کنند.
2- روش بارن و کنی کار نکرده ایم.
3- این بسته آموزشی ویدئویی را تهیه نمایید: https://www.eviews-iran.ir/product/f-limer-hausman/
4- با توجه به خطای داده شده، همسانی واریانس را با روشهای دیگر آن آزمون کنید. یا اینکه متغیرهای داخل مدل را تغییر دهید.
با سلام
برای 5 سال و 5 مقطع هم می توان از داده های پانلی استفاده کرد ؟
آیا PMCMC را می توان روی داده های پانلی در برنامه R اجرا کرد؟
سلام. 1- بله
2- در خصوص نرم افزار آر اطلاعاتی ندارم. سایر دوستان اعلام نظر داشته باشند.
با عرض سلام خدمت استاد گرامی
من برای پایان نامم از داده های پنلی استفاده کردم و روش تخمین GMM رو بکار می برم.
این وسط وقتی تخمینو میزنم داده هام همخونی ندارن و واقعا نمیدونم ایراد از کجاست (مشکل prob دارن)
از داده هام تا حدودی مطمئن هستم
فقط میخواستم بدونم مراحلی که باید برم به چه صورت هستش؟
ممنون میشم جوابو برام ایمیل کنید
با تشکر
سلام و وقت بخیر، متاسفانه روش GMM کار نکردیم و تسلط نداریم. تا جایی که قبلا یادم هست برای این روش کتاب و منبع فارسی هم نتوانستم پیدا کنم.
اگر از دوستان فردی منبعی خوب برای آموزش این روش دارد در اختیار سایرین قرار دهد.
سلام وقت بخیر. آیا می توان داده های پنلی را در نرم افزار pls انجام داد؟
سلام. نه نمی شود. نرم افزار اسمارت پی ال اس برای مدل سازی معادلات ساختاری است و داده های پرسشنامه های طیف لیکرت در ان تحلیل می شود و توانایی تحلیل داده های اقتصادی را ندارد.
با سلام
میخواستم بدونم در استفاده از داده های پانلی ایا باید برای مقاطع مختلف الزاما هم واحد باشند . مثلا GDP برای یک کشور را میتوان به دلار و برای کشور دیگر را به واحد پولی دیگر تعریف کرد؟
اصلا امکان دارد که کلیه متغیرها برای یک کشور به یک واحد خاص و سایر کشورها با واحدی دیگر تعریف شوند. در تخمین دچار مشکل نمی شویم؟
با تشکر از پاسخ شما
سلام. نه اشکال ندارد که واحدها متفاوت باشند. اگر توجه داشته باشید گاه وقتی متغیرهای مستقل ما یکی قیمت ارز است، یکی میزان فروش و گاهی یک متغیر به صورت صفر و یک است. که همه را می توان در یک مدل جای داد.
با سلام و تشکر از راهنمایی شما. منظور من این است که برای یک ردیف داده مثل gdp ده کشور مختلف طی 20 سال آیا باید برای همه مقاطع(ده کشور ) gdp با واحدی یکسان گزارش شود یا اشکال ندارد که gdp هر کشور را به واحد خودش گزارش و در تخمین بکار برد؟
سلام. اینجا قاعدتا بایست واحد یکسان باشد که قیاس بین کشورها معنی دار باشد.
سلام.وقتتون بخیر. در مورد پانلGMM میشه توضیح بدین.
سلام. در این زمینه کار نکرده ایم. سایر دوستان اگر اطلاعاتی دارند ارائه نمایند. یا ارسال تا با نام خودشان در سایت قرار دهیم
سلام وقت بخیر ، در صورت امکان راهنمائی بفرمائید
داده های مربوط به شیوع مصرف سیگار در جمعیت 15 تا64 سال در استان های مختلف کشور برای 7 سال متوالی را داریم که تعداد افراد مورد مطالعه در هر سال 10000 نفر می باشد ، با توجه به اینکه نمونه های هر سال متفاوت می باشد ولی پرسشنامه یکسان می باشد ، آیا این داده ها یک پانل دیتا می باشد. اگر متغیرهائی مانند سن ، جنس ، شغل ، وضعیت تاهل …… را داشته باشیم چه آنالیزی میتوان روی این دیتا انجام داد؟
سلام. این داده های شما پانل دیتا نیستند. یک تصویر از اکسل داده های پانل در همین صفحه سایت هست، اگر داده ها با آن نظم باشند، آنگاه پانل هستند.
داده های شما اطلاعاتی آماری است که با اکسل یا spss می توان تحلیل آماری توصیفی روی آن انجام داد و طی سالهای مختلف نتیجه را مقایسه نمود.
با سلام.
لطفا راهنمایی بفرمایید.
مدل مورد بررسی من، پنل متوازن است(30×11) با ۳۳۰ مشاهده موجود.
اما پس از انجام تخمین، تعداد مشاهدات را ۳۲۲ تا اعلام می کند.unbalanced panel
سلام. احتمالا کاراکتری در داده های شما هست که باعث می شود ایویوز نتواند بخواند داده ها را. در اکسل داده ها را خوب بررسی کنید.
بهرحال هنگام خروجی گرفتن نرم افزار برخی داده ها را به دلایلی کنار می گذارد. اگر برای تعداد کمی داده این اتفاق افتاده، مشکلی نیست.
سلام و خسته نباشید بابت مطالب بسیار مفیدتون
در روش برآورد gmm؛ آیا ازمون اف لیمر و هاسمن محلی از اعراب داره کلا؟
در بحث خود همبستگی فقط آزمون سارگان و باند کافی هستش؟
من مطالعه ای که در خصوص gmm در مقالات داشتم دیدم که فقط آزمون ریشه واحد؛ سارگان؛ باند رو انجام دادند و در خصوص سایر فروض کلاسیک آزمونی رو ندیدم.ممنون میشم راهنمایی بفرمایید
سلام. روش GMM را کار نکرده ایم و فعلا نمیدانم. توجه کنید که روش GMM پانل هم داریم.
با سلام و احترام
از مطالب مفید و مختصر شما که مانع از پیچیده شدن موضوع و عدم درک درست آن می شود، متشکرم.
چنانچه داده ها در غالب اطلاعات 60 ماه مربوط به 77 شرکت در 11 متغیر جمع آوری شده باشند، پانل مربوطه چه ترکیبی خواهد داشت؟
سوال دیگر اینکه آیا داده های متغیر های مختلف می تواند شامل اعداد صحیح و برخی درصد یا اعشار باشد یا اینکه همه باید از یک نوع باشند؟
سلام. خواهش.
1- این داده های مربوط به 77 شرکت و 60 ماه، داده های پانل هستند.
2- مشکلی ندارد و لازم نیست یک نوع و یک مقیاس باشند.
سلام وقتتون بخیر من وقتی آزمون لیمر رو انجام میدم با این خطا مواجه میشم باید چیکار کنم؟
Positive or non-negative argument to function expected
سلام. چنین خطایی را حضور ذهن ندارم. مورد کمیابی است. پیشنهاد می کنم آموزش ویدئویی زیر یا آموزش جامع رگرسیون پانل دیتا را دریافت نمایید:
https://www.eviews-iran.ir/product/f-limer-hausman/
با سلام. آیا GMM یکی از انواع تخیمن های Panel Dynamics است؟
سلام. روی این آزمون کار زیادی نکردیم. تصور من این است که Panel Dynamics یکی از حالت های GMM است. GMM می تواند هم بر روی داده های پانل و هم داده های مقطعی به کار رود.
سلام
تفاوت رگرسیون پانل ایستا و پویا در چیست و چه مشترکاتی دارند؟
سلام. از پانل پویا، برای رفع خودهمبستگی استفاده می شود. در این مدل، متغیر وابسته با درجه تاخیر (لگ) در سمت راست معادله رگرسیون نیز حضور دارد.
سلام
من این مجموعه را خریداری نمودم. به قیمت 98 هزار تومان؛ آیا من همه چیز را در باره ایویوز دارم؟
تحقیق من باره محصولات زراعتی در اثر کاهش دما، باران و رطوبت. البته این تحقیق در طی یک دوره 15 ساله کار می شود. آیا این تحقیق پانل دیتا به حساب می آید؟
سلام. این بسته آموزشی جامع، همه چیز را در خصوص داده های پانلی (ترکیبی) با روش رگرسیون معمولی (OLS) در اختیار شما می گذارد. اگر داده های شما که طی 15 سال است، مربوط به مثلا چند کشور یا چند استان باشد، بله داده های شما به صورت پانلی یا ترکیبی است و می توانید از این بسته حداکثر بهره را ببرید.
دوست عزیز آیا شما مدل های PSTR فضایی کار کرده اید و اطلاعاتی دارید بنده را راهنمایی بفرمایید؟
سلام. نه متاسفانه
سلام و سپاس از حسن نیت و خدمات ارزشمند همگانی شما
سلام. بزرگوارید.
سلام ببخشید من محصول نمونه فصل ۴ پایان نامه و همچنین تحلیل نیکویی برازش رو خریداری کردم ولی هنوز جواب سوالم رو نگرفتم، جدول تجزیه و تحلیل چند متغیره که در نتیجه ی روش gmm در مقالات میارن رو چطور باید بدست اورد؟
سلام. با عرض پوزش در خصوص روش GMM فعلا اطلاعات قابل ذکری نداریم.
کلا ما آموزشی در خصوص gmm نداریم فعلا.
با عرض سلام و احترام خدمت آقای فرشچی واقعا تشکر میکنم بابت پاسخ گویی شما!بنده دو تا سوال خدمت شما داشتم
1-فرض کنید ما یک مدل رگرسیونی را برای دو نمونه تخمین زده ایم. یعنی یکبار برای نمونه ی Aو یک بار هم نمونه ی B. حالا شما فرض کنید نمونه مثلا شرکت های بورسی دو تا کشو مختلف باشند. سوال ینده اینجاست چطور می توانیم ضرایب حاصل از تخمیل مدل برای هر نمونه را مقایسه کنیم. آیا روش و آزمون خاصی وجود دارد که ما بتوانیم این ضرایب را باهم بررسی و مقایسه کنیم کنیم.؟
2-برای مشکل هم خطی یکی از را های پی بردن به مشکل هم خطی استفاده از روش VIFهست خواستم ببینم این روش برای چه داده هایی استفاده می شود و centrate , uncentreate در جدول تحلیل vif چگونه تحلیل می شود یعنی چه موقع از uncentrate و چه موقع از centrate استفاده میکنیم.
سلام. سوال 1- برای مقایسه ضرایب به نظر من می بایست هر دو رگرسیون با داده های استاندارد شده انجام شود تا بتوان به مقایسه ضرایب پرداخت.
سوال 2- من همواره از centrate در آزمون VIF استفاده کردم و نمیدانم uncentrate به چه کار می آید.
لطفا سایر دوستان نیز اعلام نظر داشته باشند.
سلام
مطالب خیلی مفید و ارزشمند را تقدیم نمودید، دست تون درد نکند.
آزمون ریشه واحد و هم انباشتگی در داده های تابلویی دارای حداقل چند مقطع و زمان باشد لازم است؟
باسپاس
سلام. خواهش
قاعده مشخصی نمی شود گفت. اما من ندیدم که در داده های تابلویی (پانل) تعداد سال کمتر از 4 باشد و مقاطع (شرکتها) کمتر از 20 تا.
سلام من پکیج فصل 4 پایان نامه خریداری کردم داده های من از ازمون اف لیمر معلوم شد که poold هستند در پایان نامه نوشتیم که داده ها پنل هستند (چون شرکت های بورسی استفاده کردم که هم مقطع هست هم زمان ) ولی با این ازمون معوم شده که poold هستند این مشکلی نیست ؟
سلام. متشکر از خرید شما
مشکلی نیست. داده های پانل دو نوع دارند یا فاقد اثرات ثابت یا تصادفی هستند (به اصطلاح پولد هستند) یا دارای اثرات ثابت و تصادفی (پانل هستند). که این امر با آزمون اف لیمر مشخص می شود.
در آموزش جامع و ویدئویی پانل دیتا به صورت کامل و مفصل تحلیل داده های پانل از سیر تا پیاز گفته شده است و بسیاری از دوستانی که خریده اند اظهار رضایت زیادی داشته اند. یا اینکه بخشی از این آموزش جامع با نام آزمون های اف لیمر و هاسمن را تهیه نمایید. که توصیه من آموزش کامل است زیرا مبحث نیکویی برازش و سایر موارد مهم همه یکجا در آموزش کامل قرار دارد و در مجموع قیمتش بسیار مناسب تر است.
با سلام
پایان نامه من در مورد رابطه علی (هشیائو) بین سه متغیر است که متغیر ها به صورت پانلی می باشد. برای تحلیل متغیرها نیاز به رابطه خاصی هست؟ یا اینکه باید یه رابطه رگرسیون خطی بین متغیرها بنویسم؟
سلام. در معدود پژوهش هایی دیده ام که پژوهش گر خودش اقدام به تعریف متغیرها و مدل رگرسیون می کند. اما به نظر من تعریف مدل رگرسیون و نوشتن رابطه آنها، بایستی بر پایه مبانی نظری محکم باشد و توصیه می کنم بر اساس مقالات معتبر علمی داخلی یا خارجی، مدل نوشته شود و بعد ازمون شود. منتها ممکنه آن مقاله در خصوص مثلا بورس شانگهای کار کرده باشه اما شما بیایید و روی بورس تهران کار کنید.
سپاس از پاسختون
ولی من الان مشکلم این هست که در هیچ مقاله ای این سه متغیر را با هم مقایسه نکردند و من هیچ را بطه ای از این سه متغیر ندیدم
پس به احتمال 95 درصد این مدل رگرسیونی قابل اقدام نیست (چون در مبانی نظری سابقه ای از آن دیده نمی شود) . با استاد مشورت نمایید و وفق نظر ایشان اقدام کنید.
سلام خسته نباشید
من داده هایم برای ایالت های آمریکا در روز های متوالی است و 4 متغیر برای پیش بینی دارم استاد به من گفته از روش پولینگ روی داده های پنل برای پیش بینی استفاده کنم و مدل های اتورگرسیو و اتورگرسیو با میانگین متحرک و هموار سازی نمایی برای تعیین بهترین مدل روی خوشه بندی های انجام شده برای هر خوشه استفاده کنم خواستم بپرسم شما اطلاعی راجع به روش پولینگ داده های پنل دارید؟
و اینکه من با چه نرم افزاری می توانم این کار را انجام دهم؟
سلام. نه متاسفانه
این روشها که گفتید با روش رایجی که ما برای داده های پانلی استفاده می کنیم و روش رگرسیون معمولی است، تفاوت دارد.
با سلام و تشکر از مطالب مفصل و روشنی که در رابطه با تخمین داده های پنلی ارائه کردید.
سوالی داشتم در رابطه با مقاطع زمانی در داده ها پنلی: حال که می توان اثرات ثابت مقطعی را با نرم افزار برآورد کرد و با هاسمن مناسب بودن برآورد را ارزیابی کرد آیا همین آزمون برای بررسی مناسب بودن برازش با درنظر گرفتن اثرات ثابت زمانی هم کاربرد دارد؟ همچنین اصولا چه زمانی ما اثرات ثابت زمانی را بررسی می کنیم؟
سلام. بله. در اصل مدل با اثرات ثابت یا اثرات تصادفی، هم بر روی مقاطع و هم بر روی زمان قابل تعریف است و بایستی انجام شود. منتها معمولا چون تعداد مقاطع (شرکتهای بورسی) از تعداد سال در داده ها بیشتر است، معمولا هنگام انجام آزمون بر لحاظ اثرات ثابت یا تصادفی برای “زمان”، نرم افزار خطا می دهد و عملا فقط می توان بر روی “مقاطع” اثرات ثابت و تصادفی را لحاظ نمود. که در آموزش ویدئویی جامع زیر، به خوبی این عملیات آموزش داده شده است:
https://www.eviews-iran.ir/product/all-panel-data/
با عرض سلام و خسته نباشید خدمت شما استاد گرامی.
من آموزش سریع رو تهیه کردم و واقعا لذت بردم از تدریس شما. بسیار سپاسگزارم.
اما دو سوال دارم:
1- آیا آزمون نرمال بودن توزیع متغیرهای وابسته و همچنین آزمون تصادفی بودن باقیمانده ها در دادههای پانلی کاربرد ندارد؟
2- در مقالات مختلف در ابتدا و در هنگام تعریف مدل. از دو طرف مدل لگاریتم میگیرند. چرا؟
خیلی ممنون میشم پاسخ بدین.
سلام. لطف دارید.
1- در داده های پانلی آزمون نرمال بودن فقط برای باقیمانده ها انجام می شود، که آن هم اگر نتیجه این باشد که نرمال نیست، اما نمودار باقیمانده ها شکلی زنگوله ای داشته باشد، با اغماض پذیرفته می شود. آزمون تصادفی بودن باقیمانده ها در کتابهای مرجع وجود ندارد و به نظرم نمی توان گفت ضروری است. اگر نتیجه آزمون تصادفی بودن باقیمانده ها خوب باشد و در تحلیل خود بگذارید، ضرری ندارد.
2- گاهی از داده ها لگاریتم گرفته می شود، که این به دلیل بزرگ بودن اعداد داده هاست تا کمی تعدیل شوند. و اینکه ممکن است نتایج برازش بهتری بدست آید. بستگی به این دارد که در مدل شما این مورد آمده باشد یا خیر.
سلام وقت بخیر
من یک مجموعه داده پنل دارم برای تعداد 40 شرکت در یک دوره زمانی 14 ساله که برآورد لوجیت پنل زده ام در جلسه پیش دفاعم از من پرسیدند چراآزمون شکست ساختاری انجام نداده اید؟ و الان دیدم که شما پاسخ داده بودید که معمولا شکست ساختاری در داده های سری زمانی آزمون میشود نه پنل دیتا آیا توضیح کاملتری میتوانید بدهید که بتوانم درجلسه دفاع مطرح کنم
با سلام و وقت بخیر
بنده در پایان نامه ام علیت دو متغیر را برای27 کشور و 30سال بررسی میکنم البته متغیرهای فرعی هم وجود دارد که تاثیر انها بر یکی از دو متعیر اصلی بررسی میشود. من باید از ازمون علیت هشیائو یا ازمون علیت بوت استروپ استفاده کنم.ایا این دو نوع علیت در ایویوز ازمون میشود یا به نرم افزار استاتا نیاز است؟ و ایا منبع فارسی مناسبی در این مورد موجود هست یا خیر؟
ممنون میشم اگر بنده را راهنمایی بفرمایید.
سلام خسته نباشید
اگر مدل پانلی random باشه و اما رگرسیون معنی دار نشه، ادامه تحلیل تکلیفش چیه؟
سلام. بدین معنی است که بهرحال مدل رگرسیونی و در نتیجه کلیه متغیرها معنی دار نیستند. و اگر فرضیات بر پایه وجود ارتباط معنی دار بوده، رد می شوند.
سلام وقت بخیر
مدل تحقیق من به این صورت است
AUDITCOMP i;t = β0 + β1 INSTi;t + β2 OWNERi;t + β3 BSi;t + β4 BIi;t + β5 PIFi;t + β6 BIGi;t + β7 FSi;t + β8 LEVi;t + β9 ROAi;t + β10 RISKi;t + β11 LOSSi;t + εi;t
استاد راهنما گفتن این مدل رو به صورت مدل وقفه ای توزیعی مبتنی بر Gmm بنویسم. امکانش هست کمکم کنید و مدل رو به این صورت برام بنویسید. با کمال تشکر
سلام.
ببخشید من مدل fixed و random رو اجرا کردم. ضرایب متغیرها و معنی داری متغیرها در هر دو مدل خییییلی زیاد مشابه هم شدند. (برای همه متغیرها با اختلاف 0.01 یا حتی 0.001) فقط R squared در حالت فیکسد 0.8 شد ولی در حالت رندوم 0.42.
با این شرایط که تقریبا دوتا مدل ضرایب کسانی رو برآورد میکنند آیا لازمه تست هاسمن رو هم انجام بدم؟
البته من انجام دادم و random رو تایید کرد. ولی از اونجایی که مدل رندوم R squared پایینی داره من میخواستم همون fixed رو انتخاب کنم. و دلیلشم مشابه بودن دوتا مدل عنوان کنم.
میتونم این کار رو انجام بدم؟
خیلی ممنونتون میشم اگه هر چه سریع تر پاسخ بدین.
سلام. موقعیت خاصی است. اما بالاخره بایستی طبق اصول برویم جلو و قاعدتا انجام آزمون های اف لیمر و بعد هاسمن الزامی است. و وفق آنها نوع مدل تعیین شود. جایی ندیدم که با توجه به ضریب تعیین در خصوص نوع مدل که فیکسد باشد یا رندم تصمیم گیری شود.
سلام وقت بخی
ممنون از وقتی که میزارید
وقتی مدل پولد باشه برای ادامه کار و برسی فروض کلاسیک و ناهمسانی واریانس و رفع ان و برسی خود همبستگی و رفع آن چه باید کرد و دستورش چی هست ؟
سلام. وقتی مدل پولد است یعنی اینکه پنل نیست، همانند حالتی که پنل هست بایستی بررسی فروض کلاسیک و ناهمسانی واریانس و امثال آن صورت پذیرد. ادامه کار با حالتی که پنل هست تفاوت خاصی ندارد.
سلام وقت تان بخیر بنده میخوام تو نرم افزار استاتا دستوری بدم که طبق آن برای باقی مانده های مثبت عدد 1 و برای باقیمانده های منفی عدد صفر بدم لطفا راهنمایی کنید
سلام و احترام
اگر دو پیش فرض (1. استقلال خطاها با مقدار دوربین واتسون 0.97 2. توزیع خطاها به نرمال نزدیک است ولی جارگ برا آن را رد میکند) رد شود. ولی باقی پیش فرض ها رعابت شده باشد. آیا مدل پانل اجرا شده در آموزش شما، قابل اجرا است؟
به عبارتی دیگر آیا رعایت نکردن پیش فرض های (استقلال خطاها و توزیع خطاها) در مدل پانل قابل چشم پوشی است؟ با توجه به کتاب افلاطونیان
سلام. در پانل دیتا تا حدی این پیش فرض ها قابل چشم پوشی است.
اما اینجا مشکل این است که مقدار دوربین واتسون خیلی پایین است. در مقالات معتبر، دیگه مقدار کمتر از 1.4 ندیده ام.
سلام من پکیج رو خریداری کردم ولی ازمون هاسمن رو انجام نمیده؟ وقتی انجام بشه احتمال برابر یک میشه ، اینجا ینی اثرات تصادفیه یا کلا بی معنی میشه؟
سلام. گاهی در هنگام کار با نرم افزار ایویوز به مواردی بر می خوریم که نرم افزار خروجی نمیده و خطا اعلام میکنه یا اینکه خروجی خارج از عرف میده. مثل همین که شما اعلام کردید که احتمال برابر یک شده.
این مساله اغلب ناشی از داده ها و تعداد متغیرهای موجود در مدل است. گاهی با حذف یک متغیر مساله برطرف می شود. یا با اصلاح و تغییراتی در داده ها (خصوصا متغیرهای مجازی یا همان دامی).
به نظرم این خروجی آزمون هاسمن با احتمال برابر یک قابل استفاده نیست. آزمون های جایگزین را پیدا کنید یا اینکه داده ها و متغیرها را مجدد بررسی داشته باشید.
مساله داده های پرت را نیز مد نظر داشته باشید که در آموزش به آن اشاره شده است. از داده های با کیفیت و دقیق استفاده کنید.
سلام
من داده ها را نرم افزار ثبت کردم ولی خروجی نهایی ضریب رگرسیون خیلی بزرگی را نشان میدهد.برای رفع این مشکل لطفا راهنمایی بفرمایید.درضمن داده ها برخی به میلیون هستند و برخی اعداد دو رقمی و تک رقمی.آنها را چطور مرتب کنم که نتیجه درست بدست آید با سپاس
سلام، با توجه به این که در آزمون های مقدماتی رگرسیون پنل دیتا با اثرات تصادفی مُنتَج شد، از صحبت بعضی از صاحب نظر ها اینطور برداشت کردم که در حالت اثرات تصادفی دیگر نیازی به بررسی واریانس ناهمسانی و خودهمبستکی نیست و عده ای غیر فعال شدن فکر کنم گزینه ای به نام gls weight و خطایی که هنگام اضافه کردن corr(ar1) به متغیر داده ها برای رفع خودهمبستگی هنگام وارد کردن داده های برای تخمین اثرات تصادفی در نرم افزار ایویوز می دهد مبنی بر همین موضوع می باشد که نیازی به بررسی های مذکور نیست
1- آیا جناب عالی هم همین نظر را دارید؟
2- اگر نظر شما اینطور نیست، در صورت واریانس ناهمسانی و وجود خودهمبستگی، با توجه به محدودیت مربوط به gls و corr(ar1) چه پیشنهادی می فرمایید؟
سلام ،موضوعی که برای پایان نامه کار میکنم دارای ۱۳ متغییر وابسته و ۹ متغییر توضیحی و مستقل هست سوال من این هست که من هر کدام از متغییر های وابسته را جداگانه تحلیل های اماری شون را مطابق اموزش های که از طریق سایت دریافت کردم انجام دادم یعنی هر کدام از متغییر های وابسته را جدا همراه متغییر های مستقل به صورت یه مدل رگرسیون در ایویوز تحلیلاش را انجام دادم فقط برای تکمیل جدول تخمین مدل دادههای تابلویی یعنی آزمون هاسمن آزمون f نمیدونم چیکار کنم یعنی نتایج احتمال همه مدلها را بیارم ?یه سری از مدلهام اثرات ثابتند وبقیه دارای اثرات تصادفی اینها را چه طور در قسمت فرضیه ازمون و تکمیل جدول اماره های ازمون لیمر و هاسمن بیارم؟