آنچه در این ویدئوی آموزشی بیان می شود، چالش برانگیزترین بخش از تحلیل رگرسیون داده های ترکیبی (پانلی) است، زیرا اکثر دانشجویان و محققان در تشخیص نوع مدل (پولد- با اثرات ثابت- با اثرات تصادفی) دارای مشکل و ابهام هستند. در اینجا به میزان کافی مباحث نظری (برای درک مناسب روش) و به میزان زیاد به صورت عملی نحوه انجام آزمونهای اف لیمر و هاسمن، که برای تشخیص نوع مدل به کار می روند، در قالب ویدئویی و با بیانی روان گفته شده است.
مدرس: سید مجتبی فرشچی، کارشناس ارشد رشته آمار اقتصادی از دانشگاه شهید بهشتی تهران و مدیریت مجموعه تخصصی اطمینان شرق با سالها تجربه انجام تحلیل های کاربردی اقتصادسنجی.
پشتیبانی و ارتباط مستقیم با مدرس (آقای فرشچی) فقط از طریق ایتا یا سروش یا روبیکا: 09155136129
مدت زمان فیلم آموزشی و فایلهای ضمیمه: 49 دقیقه، همراه با داده ها در اکسل و ورک فایل EViews. حجم فایل دانلودی 113 مگابایت.
این محصول یکی از گامهای آموزش جامع و گام به گام رگرسیون OLS داده های ترکیبی با نرم افزار EViews می باشد. پیشنهاد می شود آموزش کامل داده های پانل (با 12 گام) را دریافت نمایید تا در خصوص داده های ترکیبی همه نکات فنی را در اختیار داشته باشید و با هر سطح از اطلاعات که هستید، به صورت کامل مفهوم و روش را فرا بگیرید (از اینجا).
بلافاصله بعد از خریداری، لینک دانلود فعال می گردد. برای خریداری بر روی “افزودن به سبد خرید” کلیک نمایید:
1- سخت ترین مرحله در تحلیل داده های پانل (تابلویی)
در اين آموزش قصد داريم مهمترين گلوگاه هنگام انجام تحليل رگرسيون داده هاي پانلي را بيان کنيم. اين گلوگاه همان درک دقيق و تشخيص درست مدل به صورت تجميعي و يا مدل به صورت پانل (داراي اثرات ثابت يا تصادفي) است.
اکثر دانشجويان و محققان هنگام انجام تحليل هاي اقتصادي و يا کار با نرم افزار EViews در اين زمينه دچار مشکل و نيازمند مشاوره هستند.
بديهي است اگر مدل در اين گلوگاه تحليلي به خوبي تشخيص داده نشود، نتايج معتبر و درستي در برازش مدل بدست نخواهد آمد و به عنوان مثال، رابطه متغير مستقل با متغير وابسته و فرضيه اي که مي بايست تاييد گردد، رد مي شود. و کشف و بيان اين مساله توسط اساتيد داور در هنگام دفاع از پايان نامه دانشجو به رد شدن دفاعيه و نتايج منجر خواهد شد.
ضمن آنکه تفهيم درست اين مفاهيم و توان محقق و دانشجو در بيان اين مدلها و اين آزمون ها در جلسه دفاعيه پايان نامه کارشناسي ارشد يا دکتري، استرس دانشجو را تا حد خيلي زيادي کاهش خواهد داد و با تسلط و بدون نگراني از نتايج تحقيقات خود دفاع خواهد کرد.
2- مدلهاي رگرسيوني داده هاي پانلي (ترکيبي)
در اين بخش لازم است مباني تئوري و پايه اي آموزش داده شود. بدون درک اين مباني تئوري امکان درک کامل تحليل رگرسيون داده هاي ترکيبي وجود ندارد. بنابراين کمربندها را محکم ببنديد. با آسان ترين و گوياترين بيان اين بخش در اين ويدئو ارائه شده است و نکته خيلي پيچيده اي ندارد.
همانطور که در گامهاي قبلي اين آموزش بطور مفصل بيان شد، کلمه رگرسيون (regression) به معناي بازگشت است و رگرسيون عبارتست از بيان تغييرات متغير وابسته بر اساس متغير/متغيرهاي ديگر.
به بيان ديگر، رگرسيون عبارتست از کشف تاثير يا عدم تاثير متغيرهاي مستقل (سمت راست معادله رگرسيون) بر روي متغير وابسته (تنها متغير سمت چپ رگرسيون) در مدل زير:
در مدل فوق، Y متغير وابسته، X متغير مستقل و Zi نيز متغيري است که خصوصيات ويژه هر شرکت (ناهمگني هاي مقاطع) يا هر کشور را نشان مي دهد.
در اينجا لازم است مجدد بيان شود که ما در حال صحبت از داده هاي پانل هستيم که در اين داده ها، علاوه بر عامل زمان، شرکتهاي مختلف بازار بورس (يا کشورها) نيز به داده هاي ما هويت مي دهند. بنابراين طبيعي است که به ازاي هر شرکت يا هر کشور، خصوصيت ويژه اي در مدل داشته باشيم.
به تصوير داده ها خود در اکسل نگاهي دوباره بيندازيم. همانطور که مشاهده مي شود مي توانيم مدلي داشته باشيم که در آن به ازاي هر شرکت بورسي، خصوصيتي خاص در مدل داشته باشيم و در مدل فوق، i از يک تا 10 (داده هاي 10 شرکت را در اختيار داريم) و t از سال 2010 تا 2016 دستخوش تغيير باشد.
با برآورد ضرايب مدل فوق مي توان تک تک داده هاي خود را به فرم فوق نوشت.
در خصوص این عبارت سه حالت زیر را مي توان متصور بود:
که حالت ها به قرار زیر است:
1-2- حالت 1- مدل تجميعي (پولد- Pooled)
اگر Zi فقط شامل يک جمله ثابت باشد که براي همه گروه ها يکسان است، در اين صورت معادله به صورت زير خواهد شد:
در اين حالت، مدل تجميعي يا پولد را داريم (ناهمگني هاي مقاطع معني دار نيستند و در مدل حضور ندارند).
در رگرسيون پولد اين حقيقت که داده ها به صورت پانل هستند ناديده گرفته مي شود و با داده ها همانند داده هاي مقطعي برخورد مي گردد. يعني در اين حالت بدون توجه به مقاطع (شرکتها) و تفاوت هاي بين آنها، داده ها را مورد تجزيه و تحليل قرار مي دهيم. و تفاوت بين مقاطع را در نظر نمي گيريم.
در اين حالت رگرسيون، عرض از مبدا مشترک (آلفاي مشترک) براي تمام مقاطع (تمام شرکتها يا تمام کشورها) در نظر گرفته مي شود.
2-2- حالت 2- مدل با اثرات ثابت (fixed effect)
اگر در مدل بين مقاطع مختلف تفاوت معني دار وجود داشته باشد، و Zi با Xi (متغيرهاي مستقل در سمت راست مدل) همبستگي داشته باشد، در اين صورت براي هر گروه يک عرض از مبدأ ( ai) خواهيم داشت که معادله آن عبارتست از:
در اينجا ai=aZi است که تمام اثرات قابل مشاهده را در بر دارد و بيانگر يک ميانگين شرطي قابل تخمين مي باشد. در اين رويکرد که به آن مدل با «اثرات ثابت» مي گوييم به هر گروه يک مقدار ثابت مانند ai اختصاص داده مي شود.
در مدل با اثرات ثابت فرض مي شود که تفاوت هاي مقاطع را مي توان در جمله ثابت (عرض از مبدا) منعکس نمود. هر ai يک ضريب مجهول است بايستي برآورد گردد.
توجه نماييد که اصطلاح «ثابت» بدان معنا است که «در طول زمان تغيير نمي کند»، اما از يک مقطع (شرکت) به مقطع ديگر دچار تغيير مي شود. همچنين توجه شود که در اين حالت Corr ( ai, Xi) ≠ 0 برقرار است.
از آنجايي که مدل فوق را با استفاده از متغيرهاي مجازي مي توان بازنويسي کرد و سپس روش OLS براي برآورد ضرايب آن به کار مي رود، لذا آن را روش حداقل مربعات متغيرهاي مجازي (LSDV) نيز مي گويند.
3-2- حالت 3- مدل با اثرات تصادفي (random effect)
اگر ناهمگني هاي مقاطع (شرکتها) قابل تفکيک به ازاي هر مقطع نباشند، و اين ناهمگني ها و تاثيرات مقاطع با متغيرهاي مستقل مدل (متغيرهاي سمت راست مدل) همبستگي نداشته باشند، به عبارت ديگر اگر نتوانيم ارتباطي بين اين تاثيرات و هر يک از متغيرهاي مستقل پيدا کنيم و ناچارا بپذيريم که اين تفاوت هاي بين مقاطع ناشي از عوامل تصادفي است، آنگاه را مي توان ناشي از عوامل تصادفي فرض نمود که مستقل از Xit است.
براي هر متغير تصادفي مي توان رابطه زير را نوشت:
رابطه فوق نشان مي دهد که از دو جزء تشکيل شده است: يکي جزء مورد انتظار که فرض مي کنيم براي همه مقاطع يکسان است و عوامل تصادفي در آن نقشي ندارند و لذا آن را به صورت مي نويسيم. ديگري جزء تصادفي است که به خاطر وجود عوامل تصادفي، در اطراف a نوسان مي کند که آن را با ui نشان مي دهيم. در واقع ui برابر با است. بدين ترتيب معادله زير را خواهيم داشت:
در مدل با اثرات تصادفي، تصريح مي شود که ui عنصر تصادفي مختص هر گروه است.
توجه شود که در اين حالت Corr ( i , Xi) = 0 برقرار است. در اينجا خصوصيات مقاطع، ارتباطي با متغيرهاي توضيحي ندارند، زيرا تصادفي هستند. مثلا در بررسي خصوصيات شرکتها به اين نتيجه مي رسيم که با هم داراي تفاوت هاي قابل توجهي هستند ولي اين تفاوت ها به صورت تصادفي به وجود آمده است {ارتباطي با متغيرهاي مستقل ندارند}، زيرا عوامل بسيار زيادي در ايجاد آنها نقش داشته اند و براي ما قابل تشخيص نيستند.
3- مدل مورد بررسي در اين آموزش
همانطور که در درسها و گامهاي قبلي اعلام شد، مدل ما در اين مثال آموزشي به قرار زير است:
و در اين آموزش قصد داريم به صورت عملي تشخيص دهيم که مدل ما مي بايست کدام يک از سه نوع مدل زير باشد:
برخي به اشتباه آزمون اف ليمر را آزموني براي تعيين رگرسيون پولد در برابر رگرسيون با مدل اثرات ثابت تصور مي کنند. در حالي که اينگونه نيست و در آن مدل تجميعي (پولد) در برابر مدل پانل يا مدل با اثرات (بدون اطلاع از اينکه اثرات ثابت يا تصادفي است) آزمون مي شود.
برای انجام اين آزمون که به آن آزمون چاو نيز مي گويند، H0 و H1 به صورت زیر بیان میشود.
H0: عرض از مبدأ تمام مقاطع یکسان است.
H1: حداقل یک مقطع عرض از مبدأ متفاوت دارد.
و يا به صورت زير:
براي انجام اين آزمون به شيوه ذکر شده در ويدئوي آموزشي اقدام مي شود.
در این آزمون فرضیه H0 یعنی یکسان بودن عرض از مبداءها در مقابل فرضیه H1 یعنی ناهمسانی عرض از مبداءها قرار میگیرد. در صورتی که فرضیه H0 پذیرفته شود به معنی یکسان بودن شیبها برای مقاطع مختلف بوده و قابلیت ترکیب شدن دادهها و استفاده از مدل رگرسیون ترکیب شده مورد تأیید آماری قرار میگیرد و فرضيههاي پژوهش با استفاده از روش دادههاي تركيب شده مورد آزمون قرار خواهد گرفت. اما در صورت رد فرضیه H0 روش دادههای پانل پذیرفته میشود و فرضيههاي پژوهش با استفاده از روش دادههاي پانل آزمون ميشود.
چنانچه مدل به صورت تجميعي بود که هيچ، کار تمام است و به آزمون هاسمن نياز نيست. اما اگر مدل به صورت پانل بود، براي تشخيص مدل با اثرات ثابت يا تصادفي نياز به آزمون هاسمن است.
در این ویدئوی آموزشی به صورت عملیاتی و با مثال واقعی این آزمون به اجرا گذاشته و تحلیل شده است.
5- آزمون هاسمن: مدل با اثرات ثابت (LSDV) يا تصادفي
در صورتي كه بر اساس نتايج آزمون چاو براي هر يك از فرضيه ها، استفاده از روش دادههاي پانل مورد تأييد واقع شود، به منظور اینکه مشخص گردد کدام روش (اثرات ثابت و یا اثرات تصادفی) برای برآورد مناسبتر ميباشد (تشخیص ثابت یا تصادفی بودن تفاوتهای واحدهای مقطعی) از آزمون هاسمن استفاده میشود.
آزمون هاسمن بر پایه وجود یا عدم وجود ارتباط بین خطای رگرسیون تخمین زده شده و متغیرهای مستقل مدل استوار است. اگر چنین ارتباطی وجود داشته باشد، مدل اثر ثابت و اگر این ارتباط وجود نداشته باشد، مدل اثر تصادفی کاربرد خواهد داشت. فرضیه H0 نشان دهنده عدم ارتباط بین متغیرهای مستقل و خطای تخمین و فرضیهH1 نشان دهنده وجود ارتباط است.
به عبارت ديگر، قاعده تصميم گيري آماري به قرار زير است:
H0: بين اثرات فردي (مقاطع) و متغيرهاي توضيحي همبستگي وجود ندارد = مدل اثرات تصادفي
H1: بين اثرات فردي (مقاطع) و متغيرهاي توضيحي همبستگي وجود دارد = مدل اثرات ثابت
بنابراين رد فرض H0 (کمتر از 0.05 بودن مقدار احتمال) به معناي وجود مدل با اثرات ثابت است.
در این ویدئوی آموزشی به صورت عملیاتی و با مثال واقعی این آزمون به اجرا گذاشته و تحلیل شده است.
6- تشريح گزينه هاي قسمت Weights در Panel Option
در قسمت Weights در بخش پاييني جعبه اجراي مدل رگرسيون پانل در برگه Panel Option مي توان وزن هاي مورد نظر براي روش GLS را انتخاب نمود. در خصوص چيستي روش GLS بيان مي کنيم که در اين روش داده ها تبديل زده شده و به آنها وزن داده مي شود. اين روش در زماني به کار مي رود که ناهمساني واريانس وجود داشته باشد.
به عنوان مثال اگر گزينه Cross-section weights را انتخاب کنيم، ايويوز از روش GLS با اين فرض استفاده مي کند که ناهمساني واريانس متعلق به مقاطع است.
اگر Cross-section SUR انتخاب شود، ايويوز از روش GLS اي استفاده مي کند که ناهمساني واريانس را با توجه به همبستگي بين جملات خطاي معادلات در بين مقاطع، تخمين مي زند. همچنين با انتخاب Period weights امکان ناهمساني واريانس را در طول زمان، در نظر مي گيرد. گزينه Period SUR نيز ناهمساني واريانس را با توجه به همبستگي بين مشاهدات در داخل هر گروه منظور مي کند.
7- اثرات ثابت و تصادفي ی زماني
توجه شود که تا اينجاي کار همواره صحبت از اثرات ثابت و تصادفي مقاطع (شرکتها) مطرح بود و در خصوص زمان و اثرات مختلف آن صحبتي به ميان نيامد. البته در 95 درصد موارد تا حد فوق در پايان نامه ها از شما انتظار دارند، و عملا بسيار به ندرت ديده ام که مدل با اثرات ثابت يا تصادفي زماني به نتيجه برسد.
اما بهرحال براي اينکه گراي لازم براي بررسي هاي بيشتر به شما داده شود، لازم است بدانيد که همانند آنچه که براي مقاطع و يا شرکتها مطرح کرديم، براي زمان (سالها) نيز قابل طرح است.
اين حالت حتي به اثرات همزمان بر روي مقاطع و زمان نيز قابل تعميم است. مدل در حالت اثرات ثابت مقاطع و اثرات ثابت زماني به صورت زير است:
که در اين ويدئو اين وضعيت را بر روي مدل خود در نرم افزار ايويوز تشريح مي کنيم.
5/5 - (5 امتیاز)
1 دیدگاه برای آموزش ویدئویی اف لیمر و هاسمن (تشخیص مدل پولد، اثرات ثابت، تصادفی)
نمره 5 از 5
قاسم زاده –
سلام. فکر نکنم از این فصیح تر فردی بتوانه بیان کنه مدل پول را
1- بهترین راه ارتباط با ما ایتا یا سروش (09155136129) می باشد. زیرا قبل از هر اعلام نظری، لازم است فایلهای شما را ببینیم.
2- اگر داده هایتان پانل می باشد (مثل داده های شرکتهای بازار بورس) آموزش های ویدئویی ما، کار با نرم افزار محبوب EViews را برای شما آسان خواهد نمود، بنابراین آنرا از دست ندهید. قالب ورد فصل 3 و 4 پایان نامه پانل دیتا نیز موجود است.
3- متاسفانه فعلا امکان قبول سفارش تحلیل با ایویوز را نداریم. لطفا اگر تحلیلگر خانم مسلط به اقتصاد سنجی می شناسید به ما معرفی کنید.

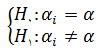



قاسم زاده –
سلام. فکر نکنم از این فصیح تر فردی بتوانه بیان کنه مدل پول را